前幾篇的基礎都是希望能幫助你在data pipeline的設計能有更多元角度的決策判斷,在做架構設計我認為最重要的是你有多少力氣去做維護、優化,不是導入很多新奇前瞻的技術就很厲害,我們聊了 OLTP 與 OLAP 的差異、Row-based 與 Columnar Database以及 In-memory Computing vs. In-database Computing,想帶給讀者的不是技術多深的細節,而是很多技術工具究竟解決了什麼問題,讓我們在導入前能盡可能客觀的評估:
有了前面的基礎,我們就來聊聊 ETL 和 ELT ,不論ETL 或是 ELT 都是 Extract、Transform以及 Load 這三個動作,但執行上順序不同、採用的技術工具也會有所不同。
從各種資料來源擷取原始資料。
透過計算轉換資料源的格式、內容,以符合服務目標的需求。
將該資料載入目標資料庫中。
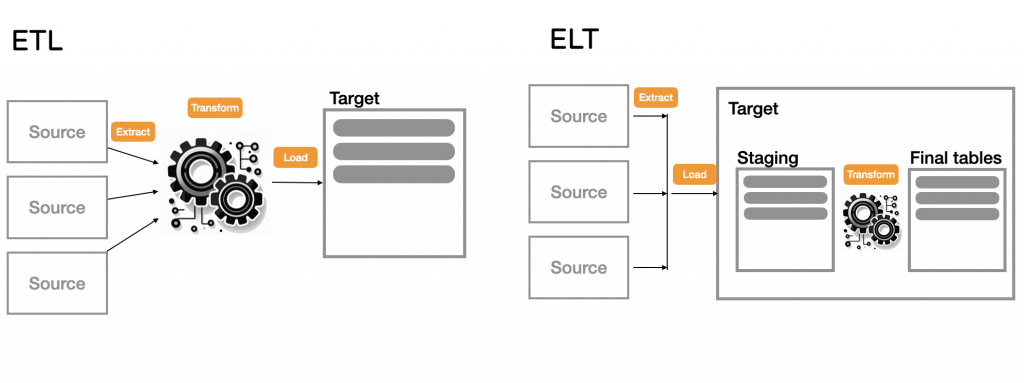
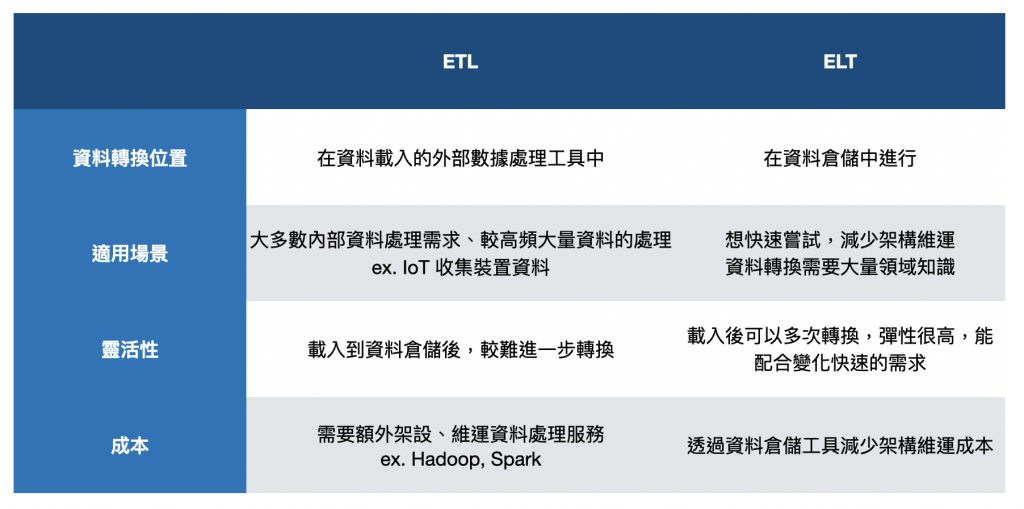
ETL 是從資料來源提取資料(Extract),在資料進入目標資料庫之前進行轉換(Transform),然後才載入(Load)到資料倉儲或目標資料庫。這個轉換過程通常在外部的 ETL 工具或專門的資料處理服務上進行。
經常透過分散式資料處理系統來實現,如我們前面聊到in-memory computing,透過 Hadoop 的 HDFS 結合 Spark 做分散式的資料儲存與平行計算,在遇到資料量提高、效能瓶頸的時候,透過增加資料計算節點,可以有效提高計算效率,但一開始需要花費比較大量時間去架設整個資料處理系統。
隨著儲存成本降低,逐步成為現代資料處理的主流,ELT 是先將資料從資料來源提取(Extract)並加載(Load)到資料倉儲或目標資料庫,然後在目標系統內進行資料的轉換(Transform)。在這個模式下,轉換過程通常是在資料倉儲內部進行的,利用資料倉儲的計算能力來完成數據處理。
透過雲端資料倉儲 (Data Warehouse) 來實現,也是前面文章提到的 Columnar Database + in-database computing,常用雲端服務如 Google BigQuery、Amazon Redshift,這些平台擁有強大的計算能力,可以高效地在內部進行數據轉換,也能相容結構化、半結構化的資料,如果你的資料多數屬於結構化、半結構化,團隊規模也較小,蠻推薦先透過這個方式來取得小成功。
我們在2018年時很認真在評估 ETL 還是 ELT ,ETL 對我們來說基礎建設能力要求很高,ELT 則是儲存成本較高,也諮詢過一些前輩,多數的共同意見是現代的儲存成本其實降低很多,建議先能快速嘗試驗證,所以後來選擇了 ELT。
當時整個公司對於產品分析、資料服務的概念幾乎是0,如果打造ETL可能會花費超過半年的時間,所以最後我希望能先快速驗證做這件事對公司是否有價值,所以選擇了 ELT,一個月內就能透過資料轉換工具,直接將 MySQL 的資料載入 GCP BigQuery 去做嘗試,讓我能先專注透過 BigQuery 來提供資料分析服務給產品、業務部門。
後來也發現真正提供資料服務以後,更花費人力的地方是去幫助產品、業務部門剛開始嘗試使用數據的夥伴,解答各種疑難雜症的問題,回顧下來把做架構的時間省下來,真正去幫助資料使用者解惑,我覺得是個蠻正確的決定。


 iThome鐵人賽
iThome鐵人賽